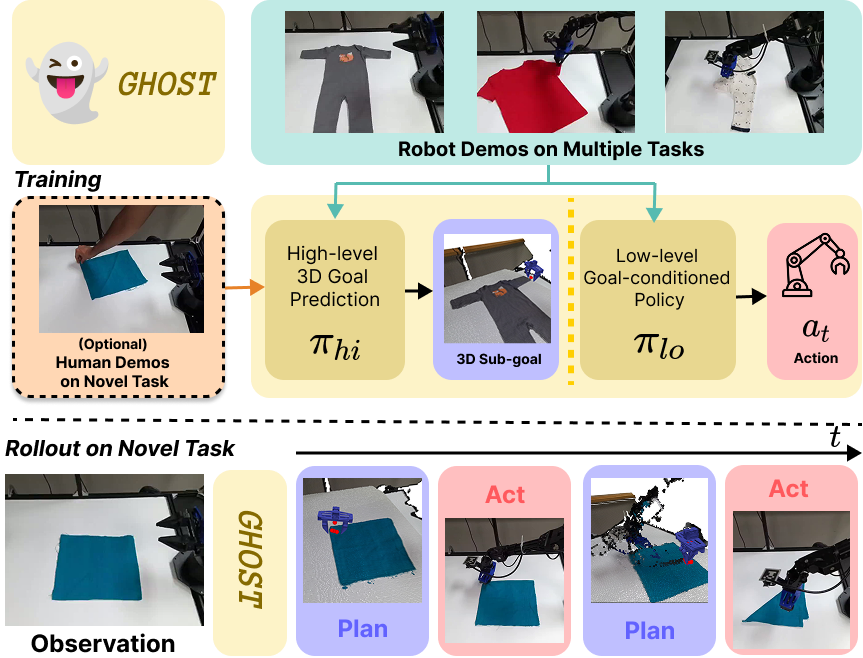
GHOST learns skills from robot teleoperation data and optionally uses human demonstrations to generalize to novel tasks. We train a hierarchical policy that decouples embodiment-agnostic goal prediction (πhi) from embodiment-specific action execution (πlo). By training πhi on both robot and human data and πlo purely on robot data, GHOST transfers learned manipulation skills to out-of-distribution tasks with third person human video demonstrations.
Further, we show that this hierarchical interface also makes it easy to incorporate human demonstrations without relying on (noisy) action retargeting. As sub-goals are largely embodiment-agnostic, we train the high-level policy on human video to specify how learned skills should be applied and composed, while keeping the low-level policy trained purely on robot data. This hierarchy enables adaptation to novel objects and task variations using a small number of human demonstrations.
Human demonstration collection. We collect human video demonstrations for out-of-distribution generalization, annotating sub-goal timesteps where key manipulation events occur (e.g., grasping, placing, folding transitions).
ALOHA Gripper
MANO Hand
End-effector representations for robot and human demonstrations. Instead of representing the gripper pose as a translation and SO(3) rotation, we represent the gripper pose as a set of 3D keypoints (red spheres): gripper base, fingertip locations, and grasping center. Left: Parallel-jaw gripper. Right: MANO hand. (Interactive - drag to rotate, scroll to zoom)
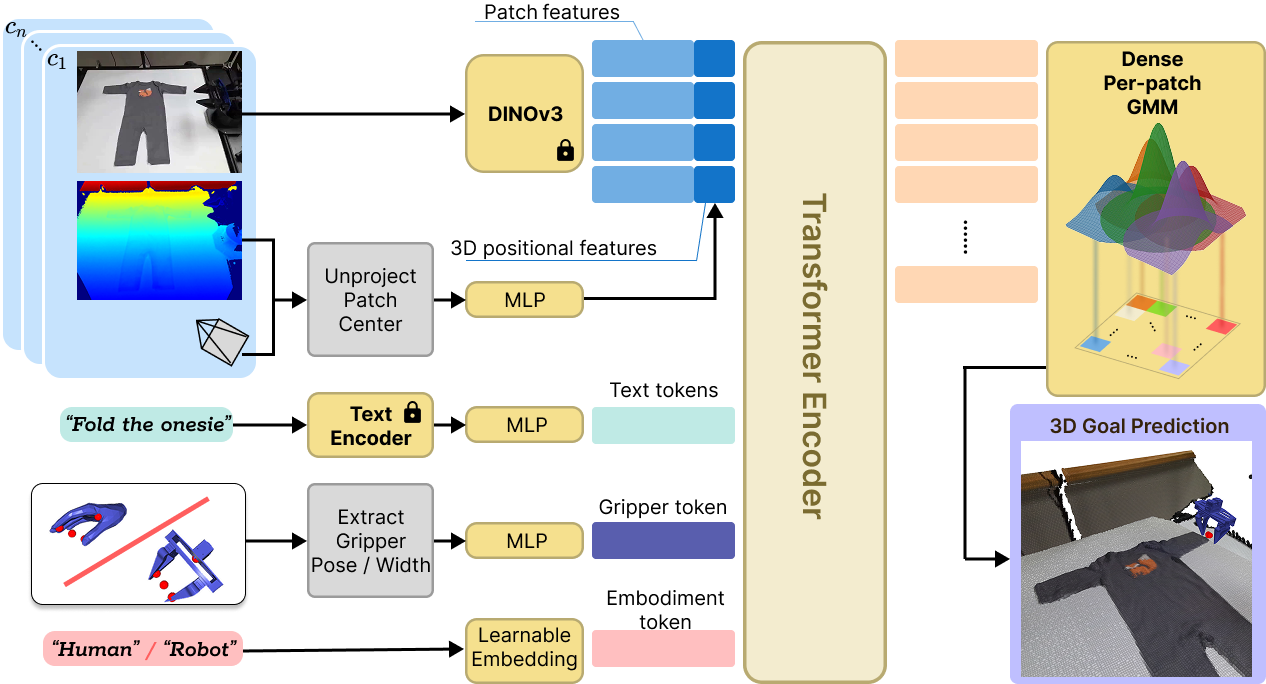
GHOST High-level sub-goal prediction architecture: RGB-D observations from multiple cameras are processed with a DINOv3 encoder, with patch tokens augmented by 3D coordinates. Additional context (gripper state, language embedding, embodiment name) is encoded via separate MLPs. A decoder-only transformer processes all tokens, with each patch predicting the GMM parameters of a 3D sub-goal distribution over end-effector keypoints.
High-level policy GMM predictions at inference. We visualize the mixture components of the GMM, with the opacity encoding mixing weight wi and arrows showing projections of 3D residuals δi from patch centers pi.

End-effector heatmap generation for goal conditioning. Predicted 3D keypoints are projected to 2D coordinates, and then converted to dense distance field heatmaps that encode spatial proximity to each keypoint.

GHOST Low-level goal-conditioned policy architecture. Images from each camera and the projected end-effector heatmap images are processed independently with ResNet encoders and concatenated along with the proprioceptive input into a global conditioning vector for the Diffusion Policy.
Interactive 4D visualization of a GHOST rollout. 3 synchronized camera views and a 3D point cloud reconstruction, powered by Rerun. Drag to rotate the 3D view, scroll to zoom, and use the timeline to scrub through the episode.
Task Overview
| Task | Data Source | # Demos | Generalization Type |
|---|---|---|---|
| Pick-and-Place | |||
| plate-on-table | Robot | 20 | — |
| plate-in-bin | Robot | 20 | — |
| mug-in-bin | Robot | 20 | — |
| mug-on-table | Human | 20 | Object combination |
| Cloth Folding | |||
| fold-onesie | Robot | 33 | — |
| fold-shirt | Robot | 50 | — |
| fold-onesie-ood | Human | 17 | Object instance |
| fold-towel | Human | 50 | Object category + Skill composition |
| Hammer Pin | |||
| hammer-pin | Human+Robot | 100 | — |
Pick and Place: GHOST generalizes pick-and-place skills to novel object combinations (mug-on-table) after training on in-distribution tasks (plate-on-table, plate-in-bin, mug-in-bin). We overlay a colormap on the image to visualize the predicted goal.
Hammer Pin: Pick up a hammer and strike the target pin. The task requires precise grasping of the hammer tool and striking the correct pin. We overlay a colormap on the image to visualize the predicted goal.
Cloth Folding: After training on folding onesies and shirts (in-distribution), GHOST shows meaningful progress in generalizing to novel object instances (fold-onesie-ood) and novel object categories with skill composition (fold-towel). We overlay a colormap on the image to visualize the predicted goal.
Pick and Place
| Method | plate-on-table | mug-on-table |
|---|---|---|
| DP | 80.0 ± 15.0 | 13.3 ± 9.2 |
| MimicPlay | 65.0 ± 15.0 | 28.3 ± 12.5 |
| GHOST (Ours - Robot Only) | 83.3 ± 10.8 | 55.0 ± 15.0 |
| GHOST (Ours) | 98.3 ± 2.5 | 63.3 ± 13.3 |
Onesie Folding
| Task | Method | 1-step | 2-step | 3-step | 4-step | Final |
|---|---|---|---|---|---|---|
| fold-onesie | DP | 90.0 | 76.7 | 53.3 | 40.0 | 10.0 ± 11.7 |
| MimicPlay | 93.3 | 76.7 | 70.0 | 70.0 | 46.7 ± 16.7 | |
| GHOST (Ours - Robot Only) | 100.0 | 100.0 | 96.7 | 86.7 | 80.0 ± 15.0 | |
| GHOST (Ours) | 100.0 | 100.0 | 100.0 | 90.0 | 83.3 ± 13.3 | |
| fold-onesie-ood (Novel Object Instance) |
DP | 76.7 | 60.0 | 46.7 | 26.7 | 10.0 ± 10.0 |
| MimicPlay | 63.3 | 36.7 | 30.0 | 20.0 | 0.0 ± 0.0 | |
| GHOST (Ours - Robot Only) | 100.0 | 100.0 | 73.3 | 60.0 | 43.3 ± 16.7 | |
| GHOST (Ours) | 100.0 | 100.0 | 93.3 | 86.7 | 56.7 ± 16.7 |
Towel Folding
| Method | fold-towel (Novel Category + Skill Composition) |
|---|---|
| MimicPlay | 16.7 ± 13.3 |
| GHOST (Ours) | 36.7 ± 16.7 |
Hammer Pin Results
| Method | hammer-pin |
|---|---|
| DP | 16.7 ± 13.3 |
| MimicPlay | 33.3 ± 16.7 |
| GHOST (Ours - Robot Only) | 50.0 ± 16.7 |
| GHOST (Ours) | 70.0 ± 16.7 |
Key Findings
Do hierarchical policies improve in-distribution performance even without human data?
Yes. For plate-on-table, nearly all methods saturate in performance, as the task is simple with sufficient training data. However, for long-horizon complex tasks, we see significant increases: on fold-onesie, performance increases from 10% (DP) to 80% (GHOST - Robot Only) final success, showing large benefits from hierarchical decomposition. Similarly, on hammer-pin, which requires precise grasping of the hammer tool and striking the correct pin, performance significantly improves from DP (16.7%) to GHOST - Robot Only (50%).
Do human demonstrations enable transferring learned skills to novel object instances, categories, and contexts?
Yes. Human demonstrations unlock meaningful OOD transfer of learned skills to novel objects and skill compositions. GHOST achieves 63.3% success on mug-on-table, a task featuring a combination of objects unseen in robot demonstrations. On fold-onesie-ood, GHOST achieves 56.7% final success vs 43.3% for GHOST - Robot Only and 0% for MimicPlay. On the hardest task of generalizing a policy to a novel object category and skill combination (fold-towel), GHOST achieves 36.7% success as compared to 16.7% with the MimicPlay baseline.
@inproceedings{krishna2026ghost,
title = {GHOST: Hierarchical Sub-Goal Policies for Generalizing Robot Manipulation},
author = {Krishna, Sriram and Eisner, Ben and Zhan, Haotian and Yuan, Ying and
Zhen, Haoyu and Gan, Chuang and Tulsiani, Shubham and Held, David},
booktitle = {Robotics: Science and Systems (RSS)},
year = {2026}
}